autofs in containers
autofs handles on-demand mounting of volumes. This is crucial for some of our storage plugins, where it is not known which volumes a Pod will need during its lifetime.
Container Storage Interface, CSI, is the industry standard for exposing storage to container workloads, and is the main way of integrating storage systems into Kubernetes. CSI drivers then implement this interface, and in our Kubernetes offerings we use it everywhere. In this blogpost we’ll discuss how we’ve made autofs work in eosxd-csi and cvmfs-csi drivers.
Motivation
Sometimes, it’s impractical if not impossible to say what volumes a Pod will need. Think Jupyter notebooks running arbitrary user scripts. Or GitLab runners. Our use cases involving access to storage systems whose different partitions, hundreds of them, can only be exposed as individual mounts. A good example of this is CVMFS, a software distribution service where each instance (repository) serving different software stacks is a separate CVMFS mount. And EOS with its many instances for different home directories and HEP experiments data falls into the same category.
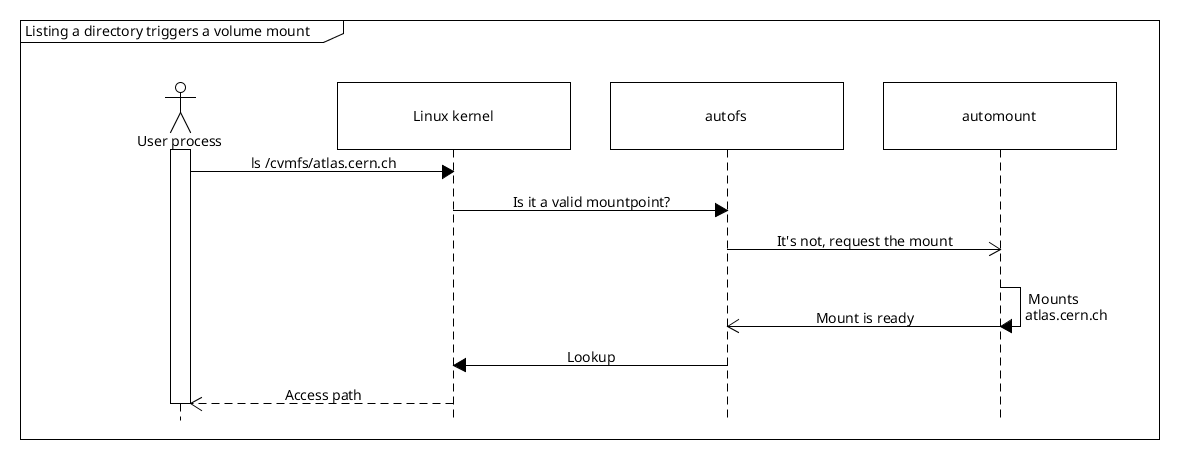
autofs is a special filesystem that provides managed on-demand volume mounting and automatic unmounting after a period of inactivity. CSI drivers eosxd-csi and cvmfs-csi we use at CERN both rely on autofs to provide access to the many CVMFS repositories and EOS instances, and save on node resource utilization when these volumes are not accessed by any Pods at the moment.
Exposing autofs-based PVs
eosx-csi and cvmfs-csi implement almost identical setups in regards to how they expose autofs, and so we’ll focus on CVMFS only, and one can assume it works the same way for eosxd-csi too. While there may be other ways to make autofs work in containers, the findings listed here represent the current state of things and how we’ve dealt with the issues we’ve found along the way when designing these CSI drivers:
- how to run the automount daemon, and where,
- how to expose the autofs root so that it is visible to consumer Pods
- how to stop consumer Pods interfering with the managed mounts inside the autofs root
- how to restore mounts after Node plugin Pod restart.
Let’s go through each of them in the next couple of sections.
Containerized and thriving
autofs relies on its user-space counterpart, the automount daemon, to handle requests to mount volumes and then resolve mount expirations when they haven’t been accessed for some time. To know where to mount what, users can define a set of config files, the so-called automount maps. They map paths on the filesystem to the mount command that shall be executed when the path is accessed. They are then read by the daemon to set everything up.
We run the automount daemon inside the CSI Node plugin Pods, as this gives us the ability to control how it is deployed and its lifetime. The maps are sourced into these Pods as a ConfigMap, leaving users and/or admins to supply additional definitions or change them entirely if they so wish. This is the indirect map we define for CVMFS:
/cvmfs /etc/auto.cvmfs
where /cvmfs marks the location where the daemon mounts the autofs root for this map entry. Then for any access in /cvmfs/<Repository>/... it runs the /etc/auto.cvmfs <Repository> executable. auto.cvmfs is a program that forms the mount command arguments. The automount daemon reads them, and runs the final mount <Arguments>, making the path /cvmfs/<Repository> available.
In summary, this is how cvmfs-csi initializes /cvmfs:
- A dedicated container in the Node plugin Pod runs
automount --foreground. With the process running in foreground it’s much easier to control its lifetime and capture its logs. - It waits until
/cvmfsis an autofs mountpoint (filesystem type0x0187). - It makes the autofs root shared with
mount --make-shared /cvmfs.
Node plugin needs to be run with hostPID: true, otherwise mount requests are not reaching the daemon:
# Running commands on the host node:
# * /var/cvmfs is the autofs root mountpoint (hostPath exposed to the Node plugin Pod).
# * The automount container runs in its own PID namespace.
# * Accessing /var/cvmfs/atlas.cern.ch does not trigger a mount in the automount daemon.
[root@rvasek-1-27-6-2-qqbsjsnaopix-node-0 /]# ls /var/cvmfs
[root@rvasek-1-27-6-2-qqbsjsnaopix-node-0 /]# ls /var/cvmfs/atlas.cern.ch
ls: cannot access '/var/cvmfs/atlas.cern.ch': No such file or directory
# Now, running automount in host's PID namespace.
[root@rvasek-1-27-6-2-qqbsjsnaopix-node-0 /]# ls /var/cvmfs/atlas.cern.ch
repo
Next, let’s see how we expose the autofs root to other Pods, in the context of a CSI Node plugin. Under the hood it’s all just bindmounts and mount sharing.
Sharing is caring, unless…
Let’s have a Pod that mounts a CVMFS PersistentVolume. As it gets scheduled on a node, kubelet invokes NodePublishVolume RPC on the cvmfs-csi Node plugin. The RPC’s request contains target_path: a hostPath where kubelet expects a new volume mount to appear, so that it can bind-mount it into the container that’s about to be started. This is where we expose the autofs root.
/cvmfs is made ready during Node plugin’s initialization (see above), so when a consumer Pod comes to the node, NodePublishVolume only needs to bind-mount the autofs root into the target_path:
mount --rbind --make-slave /cvmfs <Request.target_path>
-
--rbind: We use recursive mode because/cvmfsmay already contain mounts. Such situation is very common actually: first consumer Pod accesses/cvmfs/atlas.cern.ch; all consumers that come after must bindmount the inner mounts too. Otherwise they would show up only as empty directories, not being able to trigger autofs to mount them (because from automount’s point-of-view, the path and the mount already exists). -
--make-slave: We maketarget_patha one-way shared bindmount. There are a couple of reasons why it needs to be configured like that.By default, mountpoints are private. As such, one of the consequences is that if a new mount appears under the path, any later bindmounts of the path will not receive any (un)mount events. We need the mounts to be propagated though, otherwise if a Pod triggers a mount, it will not be able to access it.
Sharing the mountpoint both ways (with
--make-shared) would make events propagate correctly, and consumer Pods would see new inner mounts appear. But there is a catch: eventually the consumer Pods need to be deleted, triggering unmounts. The same event propagation that made inner mounts visible inside all of the bindmounts now starts working against us. Unmount events would propagate across all the bindmounts, attempting to unmount volumes not only for the Pod that was just deleted, but for all the consumer Pods. Clearly this is not something we want.To limit the blast radius of the events issued by unmounting
Request.target_path, we use slave mounts. They still receive events from the original autofs root, but when they themselves are unmounted, they don’t affect the root – it’s a one-way communication.
We have already touched on consumer Pod deletions and unmounts, but we haven’t described how is it actually done:
umount --recursive <Request.target_path>
--recursive: In general, when a Pod is deleted, its mounts need to be cleaned as well. kubelet invokesNodeUnpublishVolumeRPC on the Node plugin, unmounting the volume. In case of autofs, it’s not enough to justumount <Request.target_path>because the autofs root contains live mounts inside of it (see--rbindabove), and so this would fail withEBUSY. Instead,umount --recursiveneeds to be used.
One last thing to mention regarding unmounts is of course the mount expiry feature. We expose the inactivity timeout via a Helm chart variable, and admins can then configure its value. This didn’t need any specific setup on the CSI driver side, and so we’ll just mention what we’ve observed:
- mount expiry works well. Unmount events are correctly propagated to all slave mounts,
- when a mount expires, the automount daemon calls
umount --lazy, and so the actual unmount is deferred until there is nothing accessing it.
And lastly, consumer Pods need to set up their own mount propagation too, otherwise the events won’t be correctly propagated to the containers. This is easy enough to do:
spec:
containers:
- volumeMounts:
- name: cvmfs
mountPath: /cvmfs
mountPropagation: HostToContainer
...
This, in short, is all it took to run a basic autofs setup providing mount and unmount support for other Pods on the node. We’ve seen how cvmfs-csi starts the automount daemon, exposes the mountpoint(s) and how the consumers can let go of autofs-managed mounts when they are no longer needed. This all works great. In the next section we’ll describe what happens when the Node plugin Pod is restarted, and how we tackled the issues caused by that.
When things break
Pods can crash, get restarted, evicted. The age-old problem of persisting resources (in this case mounts) in ephemeral containers… If the Node plugin Pod goes down, so will the automount daemon that runs in it.
What can we do about it from within a CSI driver? Articles “Communicating with autofs” and “Miscellaneous Device control operations for the autofs kernel module” at kernel.org discuss autofs restore in great detail, but in short, the daemon must reclaim the ownership of the autofs root in order to be able to handle autofs requests to mount and unmount again. This is something that is supported out-of-the-box, however getting it to work in containers did not go without issues:
- automount daemon cleans up its mounts when exitting,
/dev/autofsmust be accessible,- autofs root must be exposed on the host so that it survives container restarts.
Let’s go through these one by one. We’ve mentioned that the automount daemon needs to be able to reclaim the autofs root. Under normal circumstances, once you ask the daemon to quit, it cleans up after itself and exists as asked. Cleaning up entails unmounting the individual inner mounts, followed up by unmounting the autofs root itself (analogous to umount --recursive /cvmfs). Now, one might ask how is the daemon expected to reclaim anything, if there is no autofs mount anymore?
When the Node plugin Pod is being deleted, kubelet sends SIGTERM to the containers’ main process. As expected, this indeed triggers automount’s mount clean up. This inadvertly breaks the autofs bindmounts in all consumer Pods and what’s worse, there is no way for the consumers to restore access and they all would need to be restarted. There is a way to skip the mount clean up though: instead of the SIGTERM signal, the automount’s container sends SIGKILL to the daemon when shutting down. With this “trick” the autofs mount is kept, and we are able to make the daemon reconnect and serve requests again. Additionally, a small but important detail is that the reconnect itself involves communication with the autofs kernel module via /dev/autofs device, and so it needs to be made available to the Node plugin Pod.
Related to that, the /cvmfs autofs root must be exposed via a hostPath, and be a shared mount (i.e. mount --make-shared, or mountPropagation: Bidirectional inside the Node plugin Pod manifest). Reclaiming the autofs root wouldn’t be possible if the mountpoint was tied to the Node plugin Pod’s lifetime, and so we need to persist it on the host. One thing to look out for is that if there is something periodically scanning mounts on the host (e.g. node-problem-detector, some Prometheus node metrics scrapers, …), it may keep reseting autofs’s mount expiry. In these situations it’s a good idea to exempt the autofs mountpoints from being touched by these components.
Okay, we have the root mountpoint covered, but what about the inner mounts inside /cvmfs? Normally we wouldn’t need to worry about them, but the CVMFS client is FUSE-based filesystem driver, and so it runs in user-space as a regular process. Deleting the Node plugin Pod then shuts down not only the automount daemon, but all the FUSE processes backing the respective CVMFS mounts. This causes a couple of problems:
- (a) losing those FUSE processes will cause I/O errors,
- (b) since we SIGKILL’d automount, the mounts still appear in the mount table and are not cleaned up,
- (c) automount doesn’t recognize the errors reported by severed FUSE mounts (
ENOTCONNerror code) and this prevents mount expiry from taking place.
While we cannot do anything about (a), (c) is the most serious in terms of affecting the consumers: if expiration worked, the severed mounts would be automatically taken down, and eventually mounted again (the next time the path is accessed), effectively restoring them. To work around this, we deploy yet another container in the Node plugin Pod. Its only job is to periodically scan /cvmfs for severed FUSE mounts, and in case it finds any, it unmounts them. To remount it, all it takes is for any consumer Pod on the node to access the respective path, and autofs will take care of the rest.
Conclusion
autofs is not very common in CSI drivers, and so there is not a lot of resources online on this subject. We hope this blogpost sheds a bit more light on the “how” as well as the “why”, and shows that as long as things are set up correctly, automounts indeed work fine in containers. While we have encountered numerous issues, we’ve managed to work around most of them. Also, we are in contact with the upstream autofs community and will be working towards fixing them, improving support for automounts in containers.
Summary check-list:
- Node plugin needs to be run with
hostPID: true - autofs root must be a shared mount in a hostPath
- bindmounting autofs should be done with
mount --rbind --make-slave - unmounting autofs bindmounts should be done with
umount --recursive - Node plugin Pods need access to
/dev/autofs - the automount daemon should be sent SIGKILL when shutting down
Resources: