GitLab Runners and Kubernetes: A Powerful Duo for CI/CD
Introduction
A GitLab runner is an application that works with GitLab CI/CD to run jobs in a pipeline. GitLab at CERN provides runners that are available to the whole instance and any CERN user can access them. In the past, we were providing a fixed amount of Docker runners executing in Openstack virtual machines following an in-house solution that utilized docker machine. This solution served its purpose for several years, but docker machine was deprecated by Docker some years ago, and a fork is only maintained by GitLab. The last few years CERN’s GitLab licensed users have increased and together with them, even more the number of running pipelines, as Continuous Integration and Delivery (CI/CD) is rapidly adopted by everyone. We needed to provide a scalable infrastructure that would facilitate our users’ demand and CERN’s growth and Kubernetes Runners seemed promising.
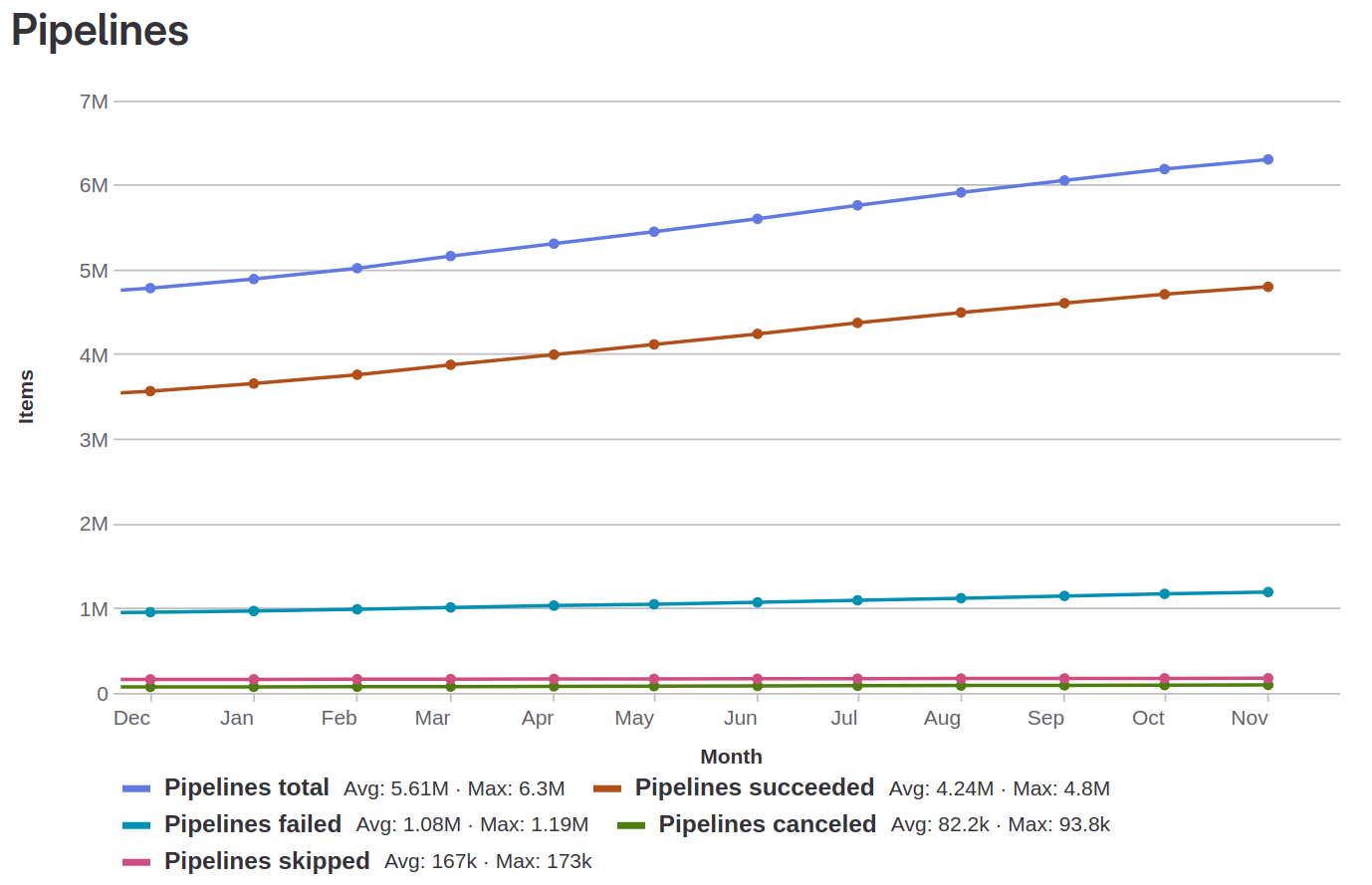
Figure 1: Evolution in the Number of Pipelines over the last year (Dec 2022 – Nov 2023)
Kubernetes+executor Runners: Our new powerful tool
The Kubernetes runners come with the advantages that Kubernetes have in terms of reliability, scalability and availability providing a robust infrastructure for runners to flourish hand by hand with our users’ activities. The new infrastructure has many advantages over the old one. It is safe to say that it suits our needs better as a big organization with a range of activities in research, IT infrastructure and development. Some of the advantages that Kubernetes Runners have are:
- Scalability: Kubernetes runners can scale from 0 to 100 pods at any given time depending on the demand across more than 20 nodes. We can also scale the cluster to any number of nodes to execute 200 jobs concurrently seamlessly, if the demand increases in the future. Here is a time frame in which instance runners went from 0 to 100 jobs in a minute.
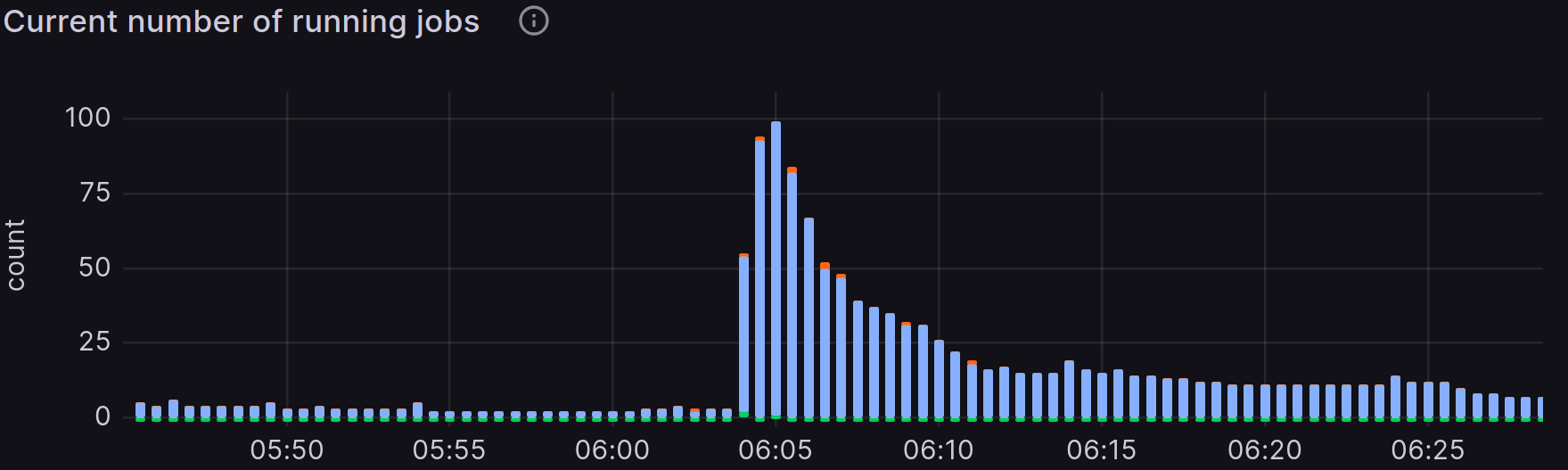
Figure 2: Grafana table of the running jobs in relation to time
Having multiple clusters gives us this advantage multiple times since the jobs are distributed in different specialized clusters depending on the users’ needs.
-
Multi Cluster Support: With multiple clusters, we are able to provide a variety of capabilities to our users based on their needs. Having 19,000 users, physicists, machine learning developers, hardware designers, software engineers means that there is not a silver bullet for shared runners. Hence, it is GitLab’s great responsibility to provide multiple instances to facilitate users’ activities. Those instances are:
- Default cluster: Generic runners that can accommodate the vast majority of jobs.
- CVMFS cluster: CVMFS stands for CernVM File System. It is a scalable, reliable, and low-maintenance software distribution service. It was developed to assist High Energy Physics (HEP) collaborations to deploy software on the worldwide-distributed computing infrastructure used to run data processing applications. The CVMFS Cluster mounts CVMFS volumes per job.
- ARM cluster: For building ARM executables with the advantages that this architecture has such as high performance, energy efficiency, and integrated security.
- FPGA cluster: At CERN, FPGAs are extensively used not only in scientific experiments but also in the operation of accelerators, where they provide specialized circuits tailored for unique applications. To support the development of these FPGA-based systems, CERN’s CI/CD infrastructure includes customized runners designed to handle FPGA development-related jobs.
- Apache Spark cluster: Apache Spark is a general-purpose distributed data processing engine and vastly used at CERN for several data analytics applications regarding research for high energy physics, AI and more.
We also have plans to incorporate new clusters in our toolbox. Those are:
- GPU cluster: Specialized runners to run jobs on GPUs for highly parallelizable workloads to accelerate our applications regarding machine learning and data processing
- Technical Network cluster: An air-gapped deployment offering connectivity for accelerator control devices and accelerator related industrial systems at CERN.
-
Easy Cluster Creation: We used Terraform to create clusters seamlessly for the different types of clusters we use as mentioned earlier. To achieve this, we used the GitLab Integration with Terraform and we are also following up OpenTofu. Furthermore, in case of a severe issue or a compromise of a cluster, we can bring the cluster down and create a new one with very few manual steps. Here is a part of our pipeline that we use to create clusters.
Figure 3: Part of the cluster creation pipeline
Architectural Overview
Let’s take a step back and see the big picture, what decisions we made and why. The following Figure 4 represents the architecture overview of the installation we implemented. The deployment of the runners has been decoupled from the GitLab cluster which has a lot of benefits:
- Cluster decoupling: Previously, the Docker executors were deployed in the same cluster as the GitLab application. Now, the runners have their own clusters which gives the advantage to maintain them separately, organize the infrastructure and runners’ configuration better per environment, and have specific end-to-end tests which allows us to verify their operability without interfering with the GitLab Application.
- Zero downtime Cluster upgrades: With this architecture we can upgrade the runners’ clusters to a more recent Kubernetes version with zero downtime by simply creating a new cluster and then registering it as an instance runner with the same tags, and finally decommissioning the old cluster. When both clusters are simultaneously running, GitLab will balance the jobs between them.
- Scaling-up: GitLab Service has a QA infrastructure to verify and assure the quality of the service before releasing. As such, this instance comes with its own set of runners which can be registered to the production instance at any time, scaling the GitLab infrastructure up to the required demand in an emergency situation.
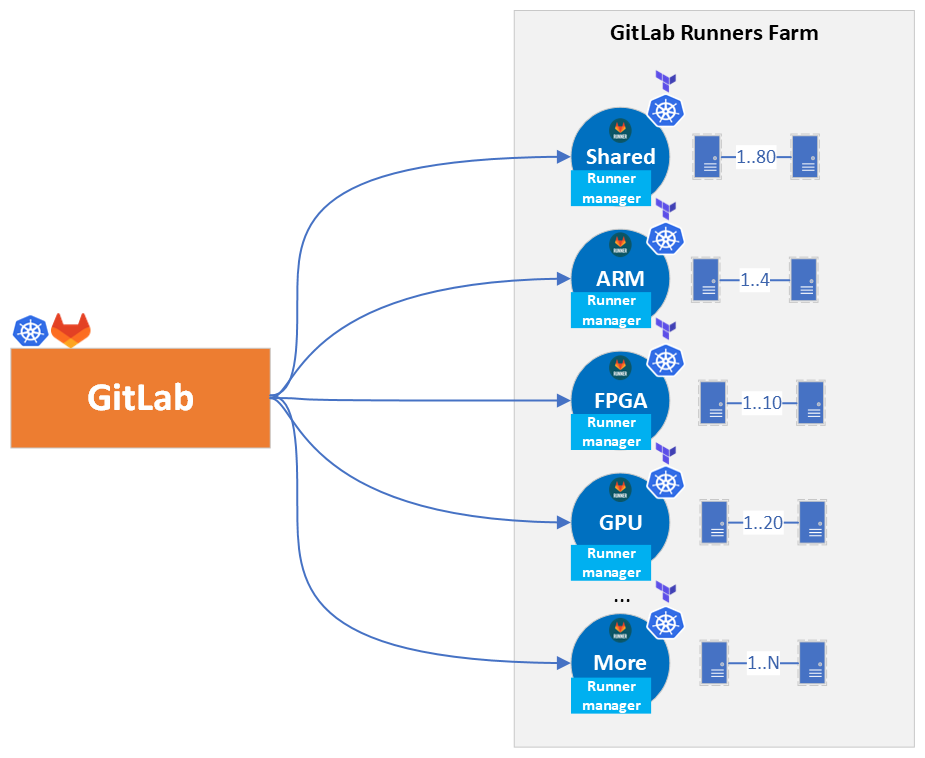
Figure 4: GitLab connection to Runners Architecture Overview
How we migrated to K8s Runners?
In order to migrate to the GitLab runners we performed a series of steps detailed next:
- Creation of a temporary tag (k8s-default)
- Opt-in offering and randomly selection of users to try them out
- Accept untagged jobs
- Finally, decommission Docker runners
Lets see the above in more detail.
![Figure 5: GitLab runners migration tImeline [2023]](/blog/2023/12/06/gitlab-runners-and-kubernetes-a-powerful-duo-for-ci/cd/images/migration-timeline.png)
Figure 5: GitLab runners migration tImeline [2023]
After setting up the clusters and registering them in GitLab, we announced a temporary tag for users interested in using the new runners, named k8s-default. Jobs were running in the new executor successfully without any problems and more and more users opted-in to try our new offering. This certainly helped us troubleshooting GitLab Runners, and start getting acquainted and embracing a very valuable experience and know-how on them.
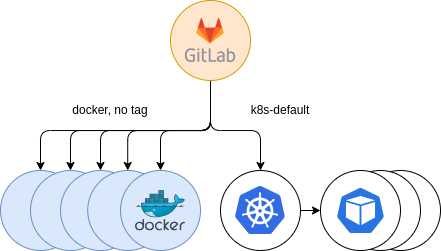
Figure 6: Initial Kubernetes providing. Opt-in
The next step was to gradually accept jobs from untagged jobs. We kept supporting previous Docker runners, in order to provide a fallback mechanism for users that, in the event of starting to use the new Kubernetes runners, experienced some errors. Thus, users using the docker tag in their .gitlab-ci.yml configuration file, would automatically land in the Docker runners, while those with untagged jobs, in addition to the k8s-default tag, started landing in the new Kubernetes runners. This gave us some insights of problems that could occur and to solve them before the full migration.
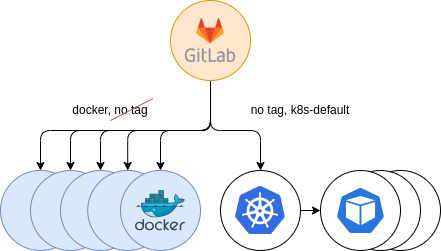
Figure 7: Secondary Kubernetes providing. Parallel to Docker
The last step was to decommission the old runner tags and move everything to the new infrastructure.
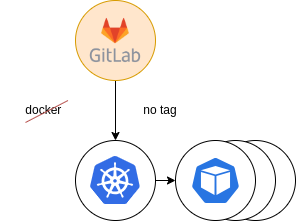
Figure 8: Final providing. Docker decommission
As a result, the Kubernetes runner accepted all the load and users that didn’t migrate to the new runners already had been forced to do it.
Errors and pitfalls
Such a big migration to the new runners had some problems and pitfalls that we discovered as we went through. Several analysis, investigations and communication with users helped us address them, aiming at providing a stable environment for our community. Here are some of the tricky problems we solved:
- Ping: Ping was disabled by default and some jobs were failing. This is caused by the security hardening Kubernetes has which disables all sysctls that may be used to access kernel capabilities of the node and interfere with other pods, including the NET_RAW capability which includes all network sysctls for the pod.
- CVMFS: There was a missing configuration in the Kubernetes configmap that was setting up the mount to the CVMFS file system, but thanks to our colleagues from the Kubernetes Team this has been solved in recent versions of CERN Kubernetes clusters (>=1.26). New clusters will benefit from this improvement.
- IPV6: The new runners are mainly using IPV6 addresses and some users that used IPV4 experienced problems in test cases that run lightweight web servers in, for example, address 127.0.0.1. This is because the pods run their own private network while the Docker runners used the host’s one.
- Entrypoint: The entrypoint in a Docker image is not executed by default due to the recent feature flag introduced in the new GitLab runners based on Kubernetes about honoring (or not) the entrypoint (FF_KUBERNETES_HONOR_ENTRYPOINT). This was not the case for Docker runners, where all runners were executing the entrypoint script in the beginning of the job. It led users into a situation where they hit a limitation, when after honoring the entrypoint of a Dockerfile, this entrypoint contained environment variables defined in the GitLab CI/CD variables. This approach is not valid anymore, and GitLab recommends using/moving the content of this entrypoint to the before_script keyword whenever possible.
- Ulimit Issue: The new Kubernetes cluster we created sets the limit of the file descriptors (ulimit) of the pods that it spawns to the maximum number possible. This is due to a default configuration in the container runtime (in our case, containerd), that in recent versions of Kubernetes, set its limit to
Infinity, the highest possible value. This caused some pods to run really slow and users complained that their jobs, which previously ran in minutes, now hang and after an hour the job was killed. This issue was challenging to address, but it was mainly related to images based on CentOS7, thus needing a lower limit to operate properly, as per this kernel bug. Nevertheless, thanks to the “pre_build_script” setting available in the GitLab Runners configuration, we could “inject” an appropriate ulimit value for all jobs, working around the issue.
Furthermore, we ran into many GitLab bugs that we raised with GitLab’s developers to be assessed, such as an issue that does not allow users to see environment variables in the Terminal or missing documentation that is crucial for customers.
As a result, CERN is becoming a more prominent figure and valued collaborator in the GitLab community through all our contributions and presence.
Security
When we transitioned from Docker runners to Kubernetes runners, it brought a significant improvement in security through the implementation of the UserNamespacesStatelessPodsSupport feature. This feature offered a substantial enhancement to the security of containerized workloads compared to the older Docker setup.
With UserNamespacesStatelessPodsSupport in Kubernetes, we were able to establish a clear separation between containerized applications and the underlying host system by running pods and containers with different user and group IDs than the host system, and by mapping them to different user namespaces. This was a security measure as it mitigated, among others, the risks associated with running containers as the root user on the host system, which could be exploited by malicious actors, potentially leading to the entire system being compromised. The implementation of UserNamespacesStatelessPodsSupport enabled users to effectively isolate containers and their workloads from the host system, thereby enhancing overall system security.
We are committed to the continuous enhancement of our security measures, with a proactive approach to implementing additional safeguards as soon as they become available. For example, it is planned to disable umask 0000 for the Kubernetes runners pods, adopting and going a step further with the security measures and best practices that have been already implemented in docker machine executor runners.
Future Security Hardening
We are actively collaborating with the CERN Security Team to establish comprehensive Security Policies for projects. These security policies are designed to enforce best practices and keep workflows up-to-date. Our collaboration with the CERN Security Team aims to establish a framework that ensures user compliance and promotes a security-conscious culture in our environment. We will talk more about security policies on a separate topic in the near future.
Conclusion and Future plans
Ultimately, with the GitLab Kubernetes runners, we managed to vastly improve the number of concurrent jobs being executed, support different workflows and cut the operational cost of the infrastructure. As we mentioned above, decoupling the clusters speeds up vastly the way we deploy, test and provide the runners, gaining in maintainability aspects.
Our future plans include the provisioning of privileged Kubernetes runners that will set the tombstone in the old docker machine runners and will complete the turnover for Kubernetes runners. It will be challenging, but we are determined to accomplish this following GitLab’s decisions and best practices.
All in all the Git Service is proud of providing our users with an exceptional infrastructure that facilitates the needs of the huge CERN scientific community. We would like to wholeheartedly thank the users that supported us with this improvement and helped us to find out breaking points of the new Kubernetes runners. Together, we managed to stabilize the new runners to be a powerful item in our tool case.
Happy GitLabing to all!
The GitLab Team
Ismael Posada Trobo ismael.posada.trobo@cern.ch
Konstantinos Evangelou konstantinos.evangelou@cern.ch
Subhashis Suara subhashis.suara@cern.ch
Special Thanks to
Ricardo Rocha for his suggestions and support