Efficient Access to Shared GPU Resources: Part 1
GPUs are shaping the way organizations access and use their data and CERN is not an exception. Traditional High Energy Physics (HEP) analysis and deployments are being rethought and accelerators remain the key to enabling efficient Machine Learning (ML).
In this series of blog posts we will cover the use cases and technologies that motivate and enable efficient sharing of GPUs on Kubernetes. For both on-premises and public cloud (on demand) access to accelerators, this can be a key factor for a cost effective use of these resources.
This post focuses on NVIDIA cards, similar mechanisms might be offered by other vendors.
Motivation
CERN’s main facility today is the Large Hadron Collider. Its experiments generate billions of particle collisions per second, with these numbers about to grow with planned upgrades. The result are hundreds of PetaBytes of data to be reconstructed and analized using large amounts of computing resources.


Even more data is generated from physics simulation which remains a cost effective way to guide the design and optimization of these giant machines as well as a basis to compare results with a well defined physics model.
GPUs are taking a central role in different areas:
- As a more efficient replacement for traditional CPU cores in simulation, or even to replace custom hardware with more flexible resources in online triggers.
- In ML for particle classification during event reconstruction (GNN), much faster generation of simulation data (3DGAN), reinforcement learning for beam calibration, among others.
As demand grows one important aspect is to ensure this type of (expensive) hardware is optimally utilized. This can be a challenge given:
- Workloads are often not capable of taking full advantage of the resources due to usage patterns, suboptimal code, etc. As with CPU virtualization, enabling resource sharing can mitigate this loss.
- Many of these workloads are spiky which can trigger significant waste if resources are locked for long periods. This is often the case during the interactive and development phase of the different components, or for services with uneven load.
Kubernetes has had support for different types of GPUs for a while now although not as first class resources and limited to dedicated, full card allocation. With the demand growing and Kubernetes established as the de-facto platform in many areas, multiple solutions exist today to enable concurrent access to GPU resources from independent workloads.
It is essential to understand each solution’s benefits and tradeoffs to enable an informed decision.
GPU Concurrency Mechanisms
By concurrency we mean going beyond simple GPU sharing. GPU sharing includes deployments where a given pool of GPUs is shared but each card is assigned to only one workload at a time for a limited (or not) amount of time.
The figure below summarizes the multiple concurrency options with NVIDIA cards.
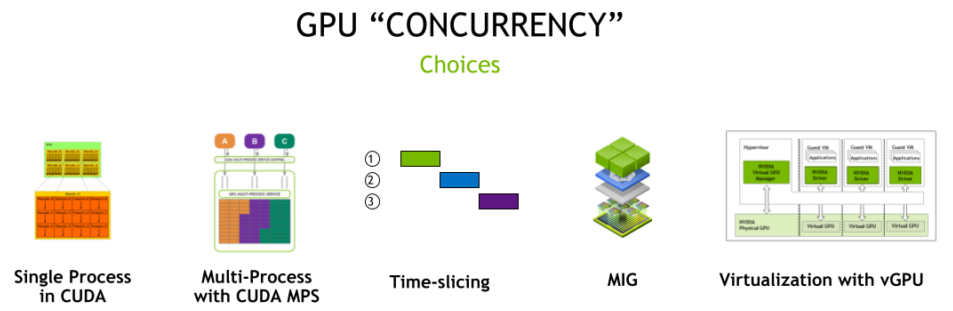
Source: NVIDIA
Out of the different mechanisms above we will not cover those that are CUDA-specific (single and multiple process CUDA) and will briefly cover the possibility of simply co-locating workloads on a single card.
Co-located Workloads
Co-locating workloads refers to uncontrolled access to a single GPU. At CERN an example of such offering is the lxplus interactive service which has dedicated nodes with GPUs. Users login to shared virtual machines each exposing a single card via PCI passthrough.
Advantages:
- The easiest way to provide GPU concurrency.
- Works by simply exposing the card via PCI passthrough.
Disadvantages:
- No memory isolation, regular OOM errors for workloads.
- Unpredictable performance.
- Limited control over the number of workloads using the GPU.
- Monitoring only of the full card, not workload specific.
Time Slicing
Time Slicing is a mechanism that allows multiple processes to be scheduled on the same GPU. The scheduler will give an equal share of time to all GPU processes and alternate in a round-robin fashion.
As a result, if the number of processes competing for resources increases, the waiting time for a single process to be re-scheduled increases as well. Below is a simplified timeline for 4 processes running on a shared GPU.
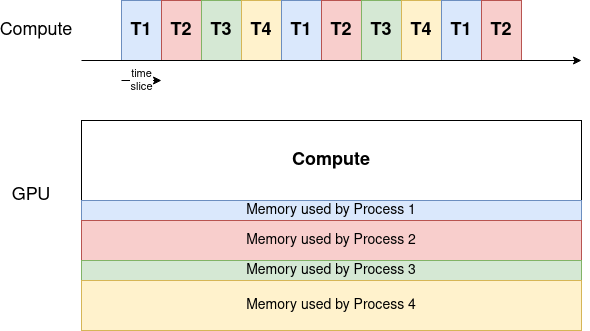
The memory is divided between the processes, while the compute resources are assigned to one process at a time.
Advantages:
- A very easy way to set up GPU concurrency.
- An unlimited number of partitions.
- Works on a very wide range of NVIDIA architectures.
Disadvantages:
- Unused computational resources remain idle during each time slice.
- No process or memory isolation, a single user can claim all memory and OOM others.
- Inappropriate for latency-sensitive applications, like for example desktop rendering for CAD workloads.
- No ability to set priorities or size slices of resources available for each workload. The time-slice period is a constant value across processes.
- Performance drop to be expected (more later in this series of blog posts).
Virtual GPU (vGPU)
vGPUs is an enterprise software from NVIDIA allowing GPU concurrency. It can be installed on GPUs in data centers or cloud and is often used to allow multiple virtual machines to access a single physical GPU.
NVIDIA provides 4 vGPU options based on different needs.
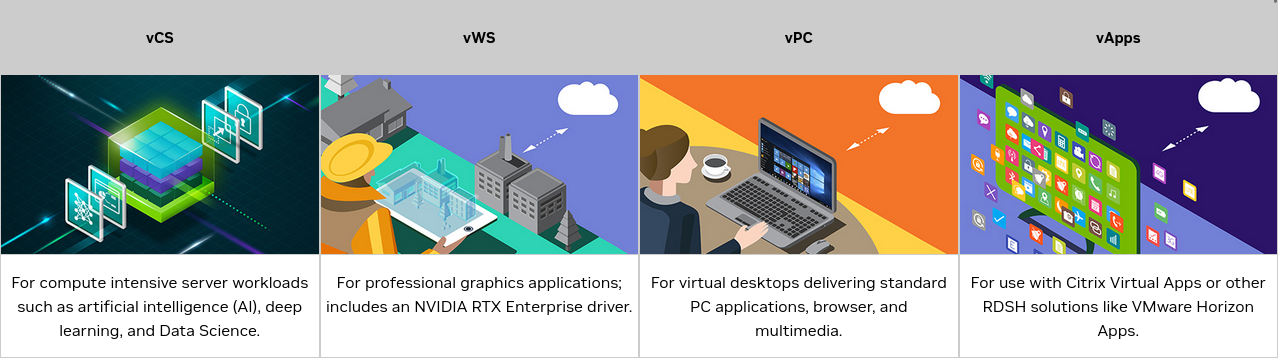
Source: NVIDIA
Advantages:
- Offers both memory bandwidth QoS and monitoring and telemetry capabilities for individual virtual partitions.
- Allows different scheduling policies, including best-effort, equal share and fixed share.
- Availability for earlier NVIDIA generations (Maxwell, Pascal and Volta in addition to more recent ones).
- Predictable performance when using fixed share scheduler.
Disadvantages:
- Enterprise solution, requires an additional license from NVIDIA.
- Performance loss due to virtualization.
- Requires a specific driver running on hypervisors.
- Partitioning still done via time-slicing, with processes being run serially and preempted at every time slice.
- No hardware isolation between workloads.
Multi-Instance GPU (MIG)
MIG technology allows hardware partitioning a GPU into up to 7 instances. Each instance has isolated memory, cache, bandwidth, and compute cores, alleviating the “noisy neighbour” problem when sharing a GPU. At the time of writing, it is available for Ampere and Hopper architecture.
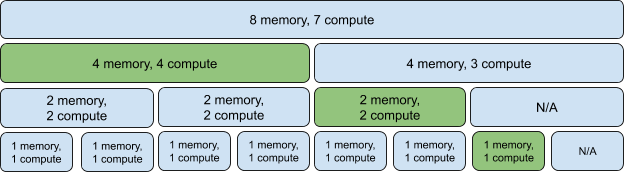
Source: Patterson Consulting
The smallest partition of the GPU is called a slice and consists of 1/8 of the memory and 1/7 of Streaming Multiprocessors (SMs) - the component that executes compute instructions on the GPU.
The possible combinations of slices are shown in the figure above, and are often referred to as Xg.Ygb denoting X compute slices and Y total memory. It is possible to mix different profiles in the same card, as denoted in green above.
Advantages:
- Hardware isolation, mean concurrent processes run securely and do not influence each other.
- Monitoring and telemetry data available at partition level.
- Allows partitioning based on use cases, making the solution very flexible.
Disadvantages:
- Only available for Ampere and Hopper architecture (as of early 2023).
- Reconfiguring the partition layout requires all running processes being evicted.
- Loss of SM cores when enabling MIG (more details to follow in our series).
- Potential loss of available memory depending on profile layout chosen.
How To Choose
Making a choice in favor of a concurrency mechanism can be hard. Depending on your use case and the resources at your disposal, the table below will help you choose the most appropriate configuration for your use case:
A big part of the table is taken from this source. Consult it for more information.
Features
| Time slicing | vGPU | MIG | |
|---|---|---|---|
| Max Partitions | Unlimited | Variable (flavor and card) | 7 |
| Partition Type | Temporal | Temporal & Physical (VMs) | Physical |
| Memory Bandwidth QoS | No | Yes | Yes |
| Telemetry | No | Yes | Yes |
| Hardware Isolation | No | No | Yes |
| Predictable Performance | No | Possible¹ | Yes |
| Reconfiguration | Not applicable | Not Applicable | When idle |
Use Cases
| Examples | Time slicing | vGPU | MIG | |
|---|---|---|---|---|
| Latency-sensitive | CAD, Engineering Applications | No | Possible¹ | Yes |
| Interactive | Notebooks | Yes² | Yes | Yes |
| Performance intensive | Simulation | No | No | Yes |
| Low priority | CI Runners | Yes | Yes (but not cost-effective) | Yes |
¹ When using the fixed share scheduler.
² Independent workloads can trigger OOM errors between each other. Needs an external mechanism to control memory usage (similar to kubelet CPU memory checks).
Support on Kubernetes
Kubernetes support for NVIDIA GPUs is provided with the NVIDIA GPU Operator.
How to use it and configure each of the concurrency mechanisms discussed will be the topic of the next post in this series.